
We can determine what page the user sees based on the visited URL in a web application with routes. There is more than one way of managing routes with modern single-page applications (SPA). In this article, we look into how hash routing works. We also explain the more modern approach to routing using the history API and the browser router. The examples will use the React Router library.
Hash router
The # has been around as a part of the URL for quite some time now. It precedes an optional fragment of the URL that points to a specific resource in the web page. Check out this example:
|
1 |
https://developer.mozilla.org/en-US/docs/Web/API/URL#properties |
When we visit the above page, the browser traverses the DOM tree looking for the element with the properties id.
|
1 2 3 |
<h2 id="properties"> <a href="#properties" title="Permalink to Properties">Properties</a> </h2> |
Since the browser can find the above element, it scrolls down the view.
There is also one significant characteristic of the hash sign in the URL. Let’s look into the Developer Tools:

Above, we can see that the browser didn’t send the #properties value to the server. It is interpreted by the browser and accessible through JavaScript.
|
1 2 |
console.log(window.location.hash); // #properties |
The above fact makes the hash a good candidate to use when creating the routing for a single-page application. With SPA, we generally provide the same initial HTML code for every page. We then use JavaScript to generate the page according to the URL.
We can easily experience the above. Let’s look into the response of the server for an application created with Create React App:
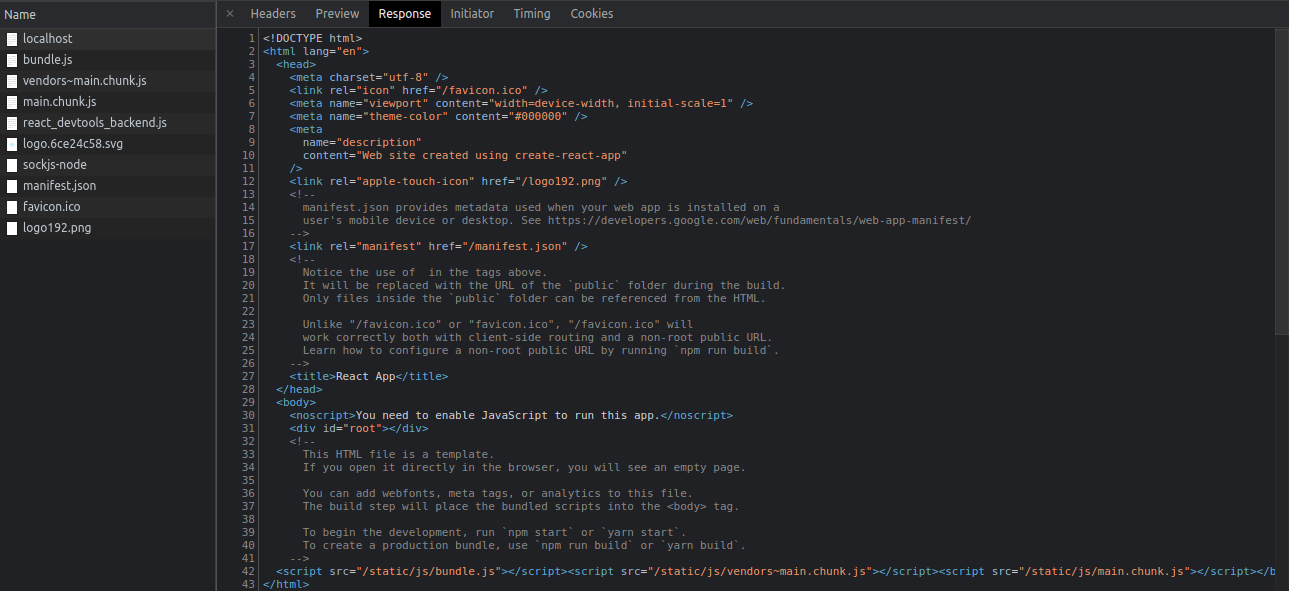
We can see that the server responds with <div id="root" /> and a set of JavaScript files. We want the above response for every route of our application. Therefore, it is quite convenient that our server will not receive the information about the exact path the user wants to access.
Using the hash router
To use the hash router with React, we can use the React Router library.
|
1 |
npm install react-router-dom |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import React from 'react'; import { HashRouter, Route } from 'react-router-dom'; import Posts from './Pages/Posts'; import LandingPage from './Pages/LandingPage'; export const App = () => ( <HashRouter> <Route exact path='/' component={LandingPage} /> <Route exact path='/posts' component={Posts} /> </HashRouter> ) |
Doing the above creates two routes for us:
- https://app.com/#/
- https://app.com/#/posts
Under the hood, React Router uses the history library. The upcoming v6.0.0 will use a version of the history library that does not support old browsers anymore. This is due to the use of the History API. This means that we will experience issues with Internet Explorer 9 and older. If for some reason, you target very old browsers, you should use an older version of the React Router.
Advantages
The main selling point of the hash routing is that the browser doesn’t send the information about the route to the web server. Thanks to that, the configuration is very straightforward.
Disadvantages
The issue with the hash routing is the fact that it looks a little out of place. This is because users are often accustomed to clean and simple URLs. Therefore, a hash in the middle might look strange.
Also, using the hash router might be considered bad for SEO.
Browser router
The alternative to the above solution is the browser router. It is built with the use of the History API in mind. With the History API, we have a straightforward way of manipulating the browser history with JavaScript.
We’ve been able to change the URL with JavaScript for quite some time now.
|
1 |
document.location.href = 'https://developer.mozilla.org/'; |
While the above works, it also reloads the page. Therefore, it makes it less than ideal for single-page applications.
We can change the window.location.hash property without the page reload, but this only changes the hash value.
With the History API, we can change the current URL without triggering the page reload.
|
1 |
window.history.pushState({}, null, 'https://developer.mozilla.org/') |
The first argument is the state that we want to associate with our new entry. It can be any data that can be serialized. For more information, check out the MDN documentation.
While the above is quite powerful, it also has some limitations. The provided URL must be of the same origin as the current page.
If you want to know more about the History API, check out this page.
Using the BrowserRouter from the React Router library looks quite straightforward:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import React from 'react'; import { BrowserRouter, Route } from 'react-router-dom'; import Posts from './Pages/Posts'; import LandingPage from './Pages/LandingPage'; export const App = () => ( <BrowserRouter> <Route exact path='/' component={LandingPage} /> <Route exact path='/posts' component={Posts} /> </BrowserRouter> ) |
The above code creates two routes for us:
- https://app.com/
- https://app.com/posts
We can notice that those URLs no longer contain the hash character. This means that even if we develop a single-page application, the browser sends the whole URL to the server. Even though we have defined a route using React Router, the web server we use to host our application might not know about it.
Accessing the https://app.com/posts route might lead to the 404 Not Found error. We need to configure our web server to respond with our React application regardless of the exact route for it to work. By doing that, we let React Router do all of the work needed to figure out what to present based on the URL.
The web server configuration will differ depending on whether you use nginx, Apache, Amazon S3, or something else.
Advantages
A big advantage of the BrowserRouter is the fact that the URLs look cleaner. They no longer include the # character, which might also be a good thing for SEO. With the BrowserRouter, our users can no longer notice right away that they are dealing with a single-page application by looking at the URL.
Disadvantages
While the BrowserRouter has a lot of advantages, it comes with the cost of requiring additional configuration. It would be cumbersome to point each URL to our React application separately. Therefore, we need to configure our web server to always respond with the same HTML for every possible URL. If we want to serve the API in the same origin, we need to create a pattern for it and don’t serve the React application if the URL contains the */api/* pattern, for example.
Summary
In this article, we’ve gone through the main characteristics of HashRouter and BrowserRouter. While doing so, we’ve also described a bit the mechanisms that work under the hood of both of them. It turns out they have their advantages and disadvantages. The official React Router documentation encourages us to use the BrowserRouter, even though it requires additional configuration on the web server side.

Great article. Thank you
Good Job, this article is amazing.
Would it be fair to say that HashRouter is faster because it does not cause requests to be sent to the server?