
- 1. Getting geeky with Git #1. Remotes and upstream branches
- 2. Getting geeky with Git #2. Building blocks of a commit
- 3. Getting geeky with Git #3. The branch is a reference
- 4. Getting geeky with Git #4. Fast-forward merge and merge strategies
- 5. Getting geeky with Git #5. Improving merge workflow with rebase
- 6. Getting geeky with Git #6. Interactive Rebase
- 7. Getting geeky with Git #7. Cherry Pick with Reflog
- 8. Getting geeky with Git #8. Improving our debugging flow with Bisect and Worktree
- 9. Getting geeky with Git #9. Understanding the revert feature
- 10. Getting geeky with Git #10. The overview of Git hooks with Husky
- 11. Getting geeky with Git #11. Keeping our Git history clean with fixup commits
As a developer, there is a high chance that you use Git every day. It means saving changes through commits. In this article, we look into what are their building blocks. This includes looking into the filesystem of Git and learning about different states of files.
Git is a Distributed Version Control System
To understand what is a commit, we need to take into account that Git is a distributed version control system.
When a Version Control System is distributed, it means that the history of the codebase is kept on a machine of every developer. Although it could function in some way without a central repository, a typical workflow includes one. When we perform operations such as committing changes or creating new branches, we work on a local version of a repository.
|
1 |
git commit -m "Making some changes" |
Doing the above does not require an Internet connection. If, for some reason, the connection to the main repository malfunctions, we can still work on our local version.
A common example of a centralized version control system is SVN. It works by having a central version of the codebase that developers commit their work to.
|
1 |
svn commit -m "Making some changes" |
The above command sends our changes straight to the centralized repository. So, to commit our changes using a centralized VCS, we need an Internet connection.
States of a file
Now we know that performing a commit saves information in our local repository. Let’s inspect more how this information is stored.
It is crucial to notice that our files might be described with the following states:
- Modified
We changed the file, but haven’t committed it yet - Staged
We marked the modified file to go into the next commit in its current version - Committed
We stored the data in our local repository
All of the files in our project are untracked by default if we didn’t include them in a previous commit. Changing a file that we don’t track does not mark it as modified.
When we stage a file for the first time, it becomes tracked. To do this, use the git add command.
|
1 |
git status |
On branch master
nothing to commit, working tree clean
|
1 2 |
touch ./new-file.txt git status |
On branch master
Untracked files:
new-file.txt
|
1 2 |
git add ./new-file.txt git status |
On branch master
Changes to be committed:
new file: new-file.txt
By doing the above, we move a specific version of our new-file.txt file to a staging area. When we create a commit, it contains files from that particular area.
An important note is that we might modify our file again, before making a commit.
|
1 2 |
echo "Hello world!" >> new-file.txt git status |
On branch master
Changes to be committed:
new file: new-file.txtChanges not staged for commit:
modified: new-file.txt
Sections of a git project
By doing the above, we now have new-file.txt in two states: modified and staged. It is possible due to the fact that when we use Git, we have three places when our files might reside:
- Working directory
It is merely the current local directory that we work on – it is where we modify our files - Staging area
A place where we store information about what will go into our next commit
- repository
When we commit our files, they end up here
A staging area is rather specific for Git. For example, Mercurial – another distributed VCS – does not implement this idea. It has just two copies of a file: the one in the working directory and the one in the repository. Git often refers to the staging area as the index. We can overwrite it as much as we see fit. This is what the git add command does.
Creating a commit
When we run the git commit command, Git creates a commit using the current contents of the staging area.
Above we mention having full copies of a particular file in three different places. It is because a commit in the Git VCS does not store just a difference between versions of the files. When we make a commit, Git takes a snapshot of the state of our project and stores a reference to it. Git treats the data as a stream of snapshots.
The above makes a lot of operations a lot faster than in systems like SVN that track just differences of a file. Git does not have to figure out the contents of a file from various diffs. A complete version of each file is available right away.
It might make our repository considerably bigger, but Git works in a way that minimizes this issue. For example, if a file hasn’t been changed, Git does not store it again.
Git objects
A repository is a collection of objects. To identify an object, we use a hash that is generated based on its contents.
For example, a hash of an empty file equals e69de29bb2d1d6434b8b29ae775ad8c2e48c5391.
|
1 2 3 4 |
touch empty git add ./empty git commit -m "added an empty file" git ls-tree master . |
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 empty
Git uses the SHA-1 hash function. When calculating the hash of a file, it adds a prefix containing the length. To confirm it, we can run the following command in a Bash terminal:
|
1 |
printf "blob 0\0" | shasum |
e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
As you can see above, the prefix also includes a type of object. Blob is a type of object that contains the content of a file.
Git also sometimes merges multiple objects into single files called packfiles. If you want to know more, check out this article by AlBlue
Also, tracking changes in big binary files might prove to be quite storage-consuming. This is why the Git Large File Storage extension exists
Tree object
A second important object type is a tree. It allows us to store multiple files together.
Let’s check out the root tree in the express-typescript repository.
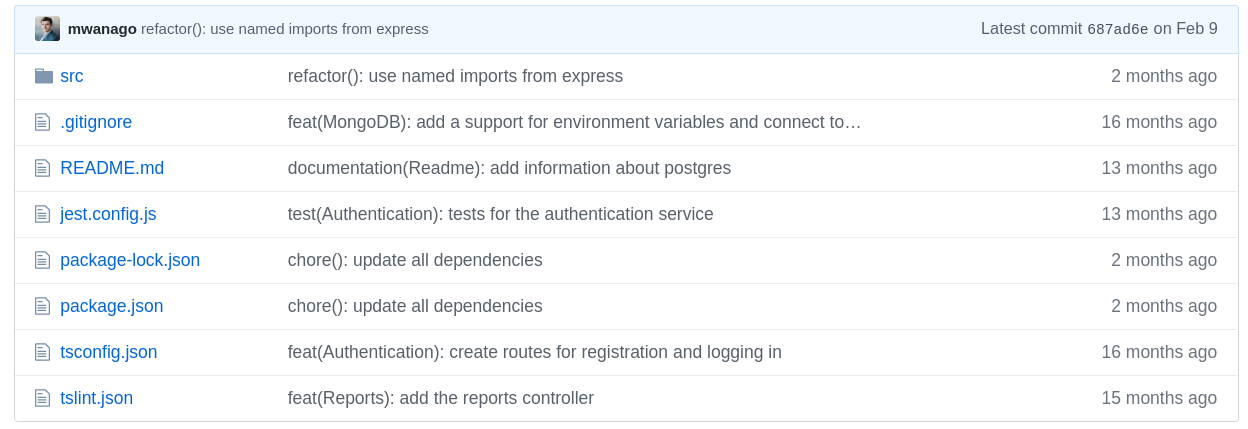
|
1 |
git cat-file -p master^{tree} |
100644 blob 5ab1f3574d380855a0a9aac2f7f2f44c812dfa72 .gitignore
100644 blob 6682d7bcd1771fe383ed47c5e44bdc4daaeeab8a README.md
100644 blob 91a2d2c0d311017438880c27890ec8d34e60d25f jest.config.js
100644 blob aae52e543b2f7f74931d6b7845b4feb00fbeccaf package-lock.json
100644 blob 19a72ce8c58b500ae9c9ef3e1984ef35c2793d51 package.json
040000 tree 82af092e7247dc6aab337d73c5dc35ba0907c124 src
100644 blob 007b58a3ae003f05ff34f02e074a4c1bc592764d tsconfig.json
100644 blob 362f99f19ed8987b44511a2675534e16f61dfe10 tslint.json
As you can see, a tree consists of references to blobs or subtrees, represented with hashes. The tree itself is also labeled using a hash.
The git cat-file -p prints the content of an object stored in the Git database
The commit object
The master^{tree} syntax that we use above specifies a tree object pointed out by the last commit on the master branch. This is our first clue in understanding what a commit is. Let’s look into the last commit in the above repository.
|
1 |
git cat-file -p 687ad6e2100d948b5296e499b968a88657120b94 |
tree f69aca9492589aa4d344963dcd146ca65d6194d7
parent 4456ad37dd0abd90dc56281bd15a2bca23a1d6fc
author mwanago <wanago.marcin@gmail.com> 1581286153 +0100
committer mwanago <wanago.marcin@gmail.com> 1581286153 +0100refactor(): use named imports from express
A commit object consists of:
- Top-level tree of the snapshot of our repository
To verify that, you can run git cat-file -p f69aca9492589aa4d344963dcd146ca65d6194d7
It yields the same result as git cat-file -p master^{tree} - The parent commit
When we run git commit, the previous commit becomes a parent.
By merging commits, we can end up with more than one parent - Author and Committer
An author is a person who wrote the code. The committer committed it - Commit message
We create an object such as the one above every time we run the git commit command. It also has its own hash.
By running the git log command, we can browse commits along with the hashes. I encourage you to experiment and browse the history of your repository.
Summary
When we run the git commit command, we create a commit in our local repository. It is based on the staging area of our project that consists of our tracked files. A commit is built with trees that consist of subtrees and blobs. Every building block is described with a hash.
Learning the above sheds some light on how the Git works. Doing so makes it avoid issues and solve them if they happen to pop up.
