
Hello! Today we tackle a very interesting topic, which is recursion. The article describes its main principles and dives deeper to uncover how does it work under the hood of the language, covering execution context and the call stack. Let’s go!
JavaScript recursion
Recursion
An act of a function calling itself. Recursion is used to solve problems that contain smaller sub-problems.
As you can see, the definition of recursion is straightforward. It is a function calling itself. If you get familiar with the concept, it might be useful for solving problems that can be broken down into smaller, similar problems. This approach is called divide and conquer.

Let’s do something practical and say you get a data structure like that and you want to get a list of all the names:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
const person = { name: 'Adam', friends: [ { name: 'John', friends: [ { name: 'William', friends: [ { name: 'Emma', } ] }, { name: 'Olivia', friends: [ { name: 'Michael', friends: [ { name: 'Eve', } ] } ] } ] } ] } |
The first thing to do is to break the problem down.
- A big problem is a task to get an array of all the names
- A small problem is a task to get just the friends of one person
One of the most important thing that our function needs is the stopping condition. Otherwise, it will run forever! To find one, try to think of a situation when the problem is the most trivial. It would be when someone has no friends at all.
Having those principals in mind, let’s create a recursive function to deal with the task.
|
1 2 3 4 5 6 7 8 9 |
function getAllTheNames(person) { const names = [ person.name ]; if(person.friends) { return names.concat( ...person.friends.map(getAllTheNames) ) } return names; } |
|
1 2 |
getAllTheNames(person); // ["Adam", "John", "William", "Emma", "Olivia", "Michael", "Eve"] |
The function has an apparent stopping condition. If there are no friends, return an array with one element. Otherwise, call the getAllTheNames function on all of the friends. In our example, the execution looks like this:
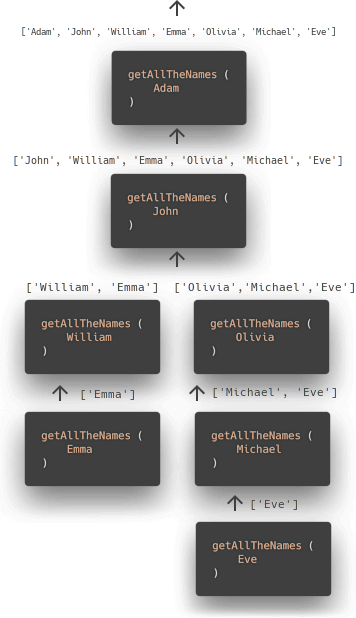
That means that the function getAllTheNames is called seven times. What does that mean to the JavaScript interpreter?
Execution context
The Execution Context is an environment where the JavaScript code executes. Every time the code runs, it has an execution context of some sort. There are three types of execution context:
- Global execution context – the base context. If the piece of code that runs is not inside of a function, it is in the global execution context. There is just one instance of it
- Functional execution context – each function has its own. Every time you call a function, JavaScript engine creates a new functional execution context.
- Eval execution context – using the eval function creates a new context.
- If you would like to know more about eval, check out Is eval evil? Just In Time (JIT) compiling
JavaScript interpreter may suspend the evaluation of the code by the execution context, and later resume it. That happens when you call a function inside of another function.
Call Stack
At any point in time, there is at most one execution context that is actually executing code. This is known as the running execution context. A stack is used to track execution contexts. The running execution context is always the top element of this stack.
As mentioned in the specification, the Call Stack (also called execution context stack) is a collection of execution contexts. At the very bottom of it is the global execution context. When you execute a function, its context is pushed on the top of the call stack. Once the function ends, the context is then taken off the stack. That means, that the functions can pile up in your call stack, and eventually, the call stack can be overflown, causing the maximum call stack size exceeded error.
Dealing with the maximum call stack size exceeded error
If you worry about the size of the call stack when writing the recursive functions, you are right. Exceeding it might be a significant problem, but that applies to situations when you are dealing with some complex recursion that will cause a lot of data to be put into the call stack.
If you want to check the size of the call stack in your node environment, you can do it with that command:
|
1 |
node --v8-options | grep -B0 -A1 stack_size |
There are some ways to approach it.
Turning a recursive function into an iterative one
You can turn every recursive algorithm into an iterative (non-recursive) one. The computer is at its heart iterative – it executes a set of instructions, one by one. Sometimes such conversion is easy and can even have better performance. The first thing to do to prevent negative consequences of recursion is to consider if it benefits your code.
If you decide that it does make your code more readable, not everything is yet lost.
Tail call optimization
Tail call optimization is a mechanism that is a part of the ES6 specification. To put thing simply, if the tail call optimization is implemented the execution contexts do not pile up in the call stack in some cases. For a detailed guide check out an article Tail call optimization in ECMAScript 6 by Axel Rauschmayer or a video Tail Call Optimization by codedamn.
An unfortunate fact is that at this moment, Safari is the only browser that implements it.
Other ways to optimize recursion
There are other ways to optimize recursion, such as trampolines. A great resource of it is Chapter 8: Recursion of the Functional-Light JavaScript by Kyle Simpson. He explains it with a lot of complex examples.
Summary
The article covered the basic principles of recursion, such as having the stopping condition and thinking in terms of dividing and conquering. To better illustrate how it affects the JavScript engine, I described the terms like the execution context and the call stack. The tips provided for handling the maximum call stack exceeded aim to help you deal with day-to-day situations in which you might find recursion to be fitting, but struggle to implement it in a performant way.
